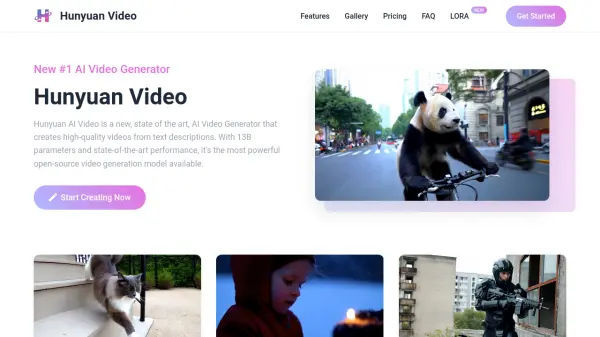
What is StepVideo T2V?
StepVideo T2V leverages a 30 billion parameter DiT architecture with 3D full attention to generate high-quality videos up to 204 frames from text prompts. It employs a deep compression Video-VAE achieving 16x16 spatial and 8x temporal compression while maintaining exceptional reconstruction quality. The model supports both English and Chinese inputs through dual text encoders, and uses Video-DPO to minimize artifacts and enhance visual output.
Available under the MIT license, StepVideo T2V can be used for commercial purposes, modified, and fine-tuned on specific domains. Performance is validated on the Step-Video-T2V-Eval benchmark, demonstrating superior text-to-video quality compared to other engines.
Features
- 30 Billion Parameters: Powers high-quality video generation with deep learning.
- 204 Frame Output: Generates videos up to 204 frames for extended scenes.
- Video-VAE Compression: Achieves 16x16 spatial and 8x temporal compression with high quality.
- Bilingual Support: Handles text prompts in English and Chinese using two text encoders.
- Video-DPO: Applies direct preference optimization to reduce artifacts and enhance visuals.
- Benchmark Proven: Evaluated on Step-Video-T2V-Eval benchmark for superior performance.
Use Cases
- Creating cinematic video clips from textual descriptions.
- Generating visual content for storytelling and narratives.
- Producing training data for video understanding models.
- Developing bilingual video content for diverse audiences.
- Enhancing video production pipelines with AI-generated footage.
FAQs
-
What is Step-Video-T2V?
Step-Video-T2V is a text-to-video generation model with 30 billion parameters that creates videos up to 204 frames from bilingual text prompts. -
How does it compress videos?
It uses a deep compression Video-VAE that achieves 16x16 spatial and 8x temporal compression while maintaining high video reconstruction quality. -
Which languages are supported?
The model supports both English and Chinese inputs through its dual text encoders. -
How is video quality enhanced?
Video-DPO (Direct Preference Optimization) is applied to reduce artifacts and improve visual quality based on human feedback. -
What are the system requirements?
Python >= 3.10, PyTorch >= 2.3 with CUDA 12.1, and multiple GPUs recommended due to high GPU memory requirements.