What is BenchLLM?
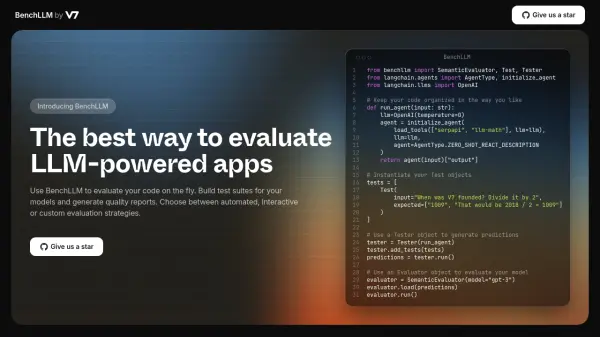
BenchLLM is a comprehensive evaluation tool designed specifically for applications powered by Large Language Models (LLMs). It provides a robust framework for developers to rigorously test and analyze the performance of their LLM-based code.
With BenchLLM, users can create and manage test suites, generate detailed quality reports, and leverage a variety of evaluation strategies, including automated, interactive, and custom approaches. This ensures thorough assessment and helps identify areas for improvement in LLM applications.
Features
- Test Suites: Build comprehensive test suites for your LLM models.
- Quality Reports: Generate detailed reports to analyze model performance.
- Automated Evaluation: Utilize automated evaluation strategies.
- Interactive Evaluation: Conduct interactive evaluations.
- Custom Evaluation: Implement custom evaluation strategies.
- Powerful CLI: Run and evaluate models with simple CLI commands.
- Flexible API: Test code on the fly and integrate with various APIs (OpenAI, Langchain, etc.).
- Test Organization: Organize tests into versioned suites.
- CI/CD Integration: Automate evaluations within a CI/CD pipeline.
- Performance Monitoring: Track model performance and detect regressions.
Use Cases
- Evaluating the performance of LLM-powered applications.
- Building and managing test suites for LLM models.
- Generating quality reports to analyze model behavior.
- Identifying regressions in model performance.
- Automating evaluations in a CI/CD pipeline.
- Testing code with various APIs like OpenAI and Langchain.