Website Downloader MCP Server
Download and archive entire websites as local, browsable directories via MCP.
Key Features
Use Cases
README
Website Downloader MCP Server
This MCP server provides a tool to download entire websites using wget. It preserves the website structure and converts links to work locally.
Prerequisites
The server requires wget to be installed on your system.
Installing wget
macOS
Using Homebrew:
brew install wget
Linux (Debian/Ubuntu)
sudo apt-get update
sudo apt-get install wget
Linux (Red Hat/Fedora)
sudo dnf install wget
Windows
- Using Chocolatey:
choco install wget
- Or download the binary from: https://eternallybored.org/misc/wget/
- Download the latest wget.exe
- Place it in a directory that's in your PATH (e.g., C:\Windows\System32)
Usage
The server provides a tool called download_website with the following parameters:
url(required): The URL of the website to downloadoutputPath(optional): The directory where the website should be downloaded. Defaults to the current directory.depth(optional): Maximum depth level for recursive downloading. Defaults to infinite. Set to 0 for just the specified page, 1 for direct links, etc.
Example
{
"url": "https://example.com",
"outputPath": "/path/to/output",
"depth": 2 // Optional: Download up to 2 levels deep
}
Features
The website downloader:
- Downloads recursively with infinite depth
- Includes all page requisites (CSS, images, etc.)
- Converts links to work locally
- Adds appropriate extensions to files
- Restricts downloads to the same domain
- Preserves the website structure
Installation
- Build the server:
npm install
npm run build
- Add to MCP settings:
{
"mcpServers": {
"website-downloader": {
"command": "node",
"args": ["/path/to/website-downloader/build/index.js"]
}
}
}
Star History
Repository Owner

User
Repository Details
Programming Languages
Tags
Join Our Newsletter
Stay updated with the latest AI tools, news, and offers by subscribing to our weekly newsletter.
Related MCPs
Discover similar Model Context Protocol servers
mcp-read-website-fast
Fast, token-efficient web content extraction and Markdown conversion for AI agents.
Provides a Model Context Protocol (MCP) compatible server that rapidly fetches web pages, removes noise, and converts content to clean Markdown with link preservation. Designed for local use by AI-powered tools like IDEs and large language models, it offers optimized token usage, concurrency, polite crawling, and smart caching. Integrates with Claude Code, VS Code, JetBrains IDEs, Cursor, and other MCP clients.
- ⭐ 111
- MCP
- just-every/mcp-read-website-fast
Urlbox MCP Server
Screenshot, PDF, HTML, and markdown generation MCP for websites.
Urlbox MCP Server enables AI clients to generate website screenshots, PDFs, and extract HTML or markdown from web pages via the Urlbox Screenshot API. It supports automated extraction of metadata, cookies, and allows local file downloads. The server is designed to be integrated with LLMs, which can use its tools to capture and process web content on demand via standardized MCP interfaces. Environment variable configuration secures API access, and multiple formats are supported for flexible output.
- ⭐ 1
- MCP
- urlbox/urlbox-mcp-server
WebScraping.AI MCP Server
MCP server for advanced web scraping and AI-driven data extraction
WebScraping.AI MCP Server implements the Model Context Protocol to provide web data extraction and question answering functionalities. It integrates with WebScraping.AI to offer robust tools for retrieving, rendering, and parsing web content, including structured data and natural language answers from web pages. It supports JavaScript rendering, proxy management, device emulation, and custom extraction configurations, making it suitable for both individual and team deployments in AI-assisted workflows.
- ⭐ 33
- MCP
- webscraping-ai/webscraping-ai-mcp-server
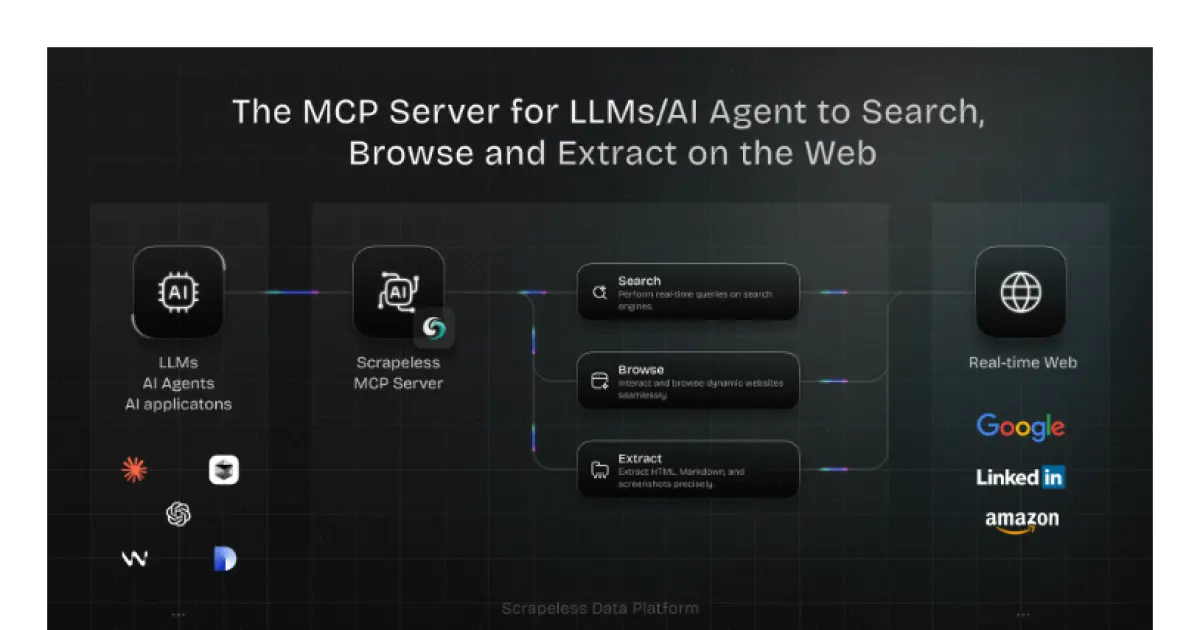
Scrapeless MCP Server
A real-time web integration layer for LLMs and AI agents built on the open MCP standard.
Scrapeless MCP Server is a powerful integration layer enabling large language models, AI agents, and applications to interact with the web in real time. Built on the open Model Context Protocol, it facilitates seamless connections between models like ChatGPT, Claude, and tools such as Cursor to external web capabilities, including Google services, browser automation, and advanced data extraction. The system supports multiple transport modes and is designed to provide dynamic, real-world context to AI workflows. Robust scraping, dynamic content handling, and flexible export formats are core parts of the feature set.
- ⭐ 57
- MCP
- scrapeless-ai/scrapeless-mcp-server
Fetcher MCP
Intelligent web content fetching and extraction using Playwright.
Fetcher MCP is a server that fetches and extracts web page content using the Playwright headless browser while supporting the Model Context Protocol. It intelligently processes dynamic web pages with JavaScript, employs the Readability algorithm to extract main content, and supports output in both HTML and Markdown formats. Designed for seamless integration with AI model environments, it offers robust parallel processing, resource optimization, and flexible deployment options including Docker.
- ⭐ 906
- MCP
- jae-jae/fetcher-mcp
Markdownify MCP Server
Convert diverse files and web content into Markdown via the Model Context Protocol.
Markdownify MCP Server offers a protocol-based server that transforms various file types—including PDF, images, audio, DOCX, XLSX, and PPTX—as well as web content like YouTube videos, Bing search results, and web pages into Markdown format. The server exposes a suite of conversion tools through a standardized interface for easy integration with applications. Optional configuration allows retrieval of Markdown files from restricted directories, and the platform supports development customization for additional tool integration. Deployment and operation are straightforward with cross-platform support (with pending Windows improvements).
- ⭐ 2,256
- MCP
- zcaceres/markdownify-mcp
Didn't find tool you were looking for?