mcp-read-website-fast
Fast, token-efficient web content extraction and Markdown conversion for AI agents.
Key Features
Use Cases
README
@just-every/mcp-read-website-fast
Fast, token-efficient web content extraction for AI agents - converts websites to clean Markdown.
![]()
![]()
Overview
Existing MCP web crawlers are slow and consume large quantities of tokens. This pauses the development process and provides incomplete results as LLMs need to parse whole web pages.
This MCP package fetches web pages locally, strips noise, and converts content to clean Markdown while preserving links. Designed for Claude Code, IDEs and LLM pipelines with minimal token footprint. Crawl sites locally with minimal dependencies.
Note: This package now uses @just-every/crawl for its core crawling and markdown conversion functionality.
Features
- Fast startup using official MCP SDK with lazy loading for optimal performance
- Content extraction using Mozilla Readability (same as Firefox Reader View)
- HTML to Markdown conversion with Turndown + GFM support
- Smart caching with SHA-256 hashed URLs
- Polite crawling with robots.txt support and rate limiting
- Concurrent fetching with configurable depth crawling
- Stream-first design for low memory usage
- Link preservation for knowledge graphs
- Optional chunking for downstream processing
Installation
Claude Code
claude mcp add read-website-fast -s user -- npx -y @just-every/mcp-read-website-fast
VS Code
code --add-mcp '{"name":"read-website-fast","command":"npx","args":["-y","@just-every/mcp-read-website-fast"]}'
Cursor
cursor://anysphere.cursor-deeplink/mcp/install?name=read-website-fast&config=eyJyZWFkLXdlYnNpdGUtZmFzdCI6eyJjb21tYW5kIjoibnB4IiwiYXJncyI6WyIteSIsIkBqdXN0LWV2ZXJ5L21jcC1yZWFkLXdlYnNpdGUtZmFzdCJdfX0=
JetBrains IDEs
Settings → Tools → AI Assistant → Model Context Protocol (MCP) → Add
Choose “As JSON” and paste:
{"command":"npx","args":["-y","@just-every/mcp-read-website-fast"]}
Or, in the chat window, type /add and fill in the same JSON—both paths land the server in a single step. 
Raw JSON (works in any MCP client)
{
"mcpServers": {
"read-website-fast": {
"command": "npx",
"args": ["-y", "@just-every/mcp-read-website-fast"]
}
}
}
Drop this into your client’s mcp.json (e.g. .vscode/mcp.json, ~/.cursor/mcp.json, or .mcp.json for Claude).
Features
- Fast startup using official MCP SDK with lazy loading for optimal performance
- Content extraction using Mozilla Readability (same as Firefox Reader View)
- HTML to Markdown conversion with Turndown + GFM support
- Smart caching with SHA-256 hashed URLs
- Polite crawling with robots.txt support and rate limiting
- Concurrent fetching with configurable depth crawling
- Stream-first design for low memory usage
- Link preservation for knowledge graphs
- Optional chunking for downstream processing
Available Tools
read_website- Fetches a webpage and converts it to clean markdown- Parameters:
url(required): The HTTP/HTTPS URL to fetchpages(optional): Maximum number of pages to crawl (default: 1, max: 100)
- Parameters:
Available Resources
read-website-fast://status- Get cache statisticsread-website-fast://clear-cache- Clear the cache directory
Development Usage
Install
npm install
npm run build
Single page fetch
npm run dev fetch https://example.com/article
Crawl with depth
npm run dev fetch https://example.com --depth 2 --concurrency 5
Output formats
# Markdown only (default)
npm run dev fetch https://example.com
# JSON output with metadata
npm run dev fetch https://example.com --output json
# Both URL and markdown
npm run dev fetch https://example.com --output both
CLI Options
-p, --pages <number>- Maximum number of pages to crawl (default: 1)-c, --concurrency <number>- Max concurrent requests (default: 3)--no-robots- Ignore robots.txt--all-origins- Allow cross-origin crawling-u, --user-agent <string>- Custom user agent--cache-dir <path>- Cache directory (default: .cache)-t, --timeout <ms>- Request timeout in milliseconds (default: 30000)-o, --output <format>- Output format: json, markdown, or both (default: markdown)
Clear cache
npm run dev clear-cache
Auto-Restart Feature
The MCP server includes automatic restart capability by default for improved reliability:
- Automatically restarts the server if it crashes
- Handles unhandled exceptions and promise rejections
- Implements exponential backoff (max 10 attempts in 1 minute)
- Logs all restart attempts for monitoring
- Gracefully handles shutdown signals (SIGINT, SIGTERM)
For development/debugging without auto-restart:
# Run directly without restart wrapper
npm run serve:dev
Architecture
mcp/
├── src/
│ ├── crawler/ # URL fetching, queue management, robots.txt
│ ├── parser/ # DOM parsing, Readability, Turndown conversion
│ ├── cache/ # Disk-based caching with SHA-256 keys
│ ├── utils/ # Logger, chunker utilities
│ ├── index.ts # CLI entry point
│ ├── serve.ts # MCP server entry point
│ └── serve-restart.ts # Auto-restart wrapper
Development
# Run in development mode
npm run dev fetch https://example.com
# Build for production
npm run build
# Run tests
npm test
# Type checking
npm run typecheck
# Linting
npm run lint
Contributing
Contributions are welcome! Please:
- Fork the repository
- Create a feature branch
- Add tests for new functionality
- Submit a pull request
Troubleshooting
Cache Issues
npm run dev clear-cache
Timeout Errors
- Increase timeout with
-tflag - Check network connectivity
- Verify URL is accessible
Content Not Extracted
- Some sites block automated access
- Try custom user agent with
-uflag - Check if site requires JavaScript (not supported)
License
MIT
Star History
Repository Owner

Organization
Repository Details
Programming Languages
Tags
Topics
Join Our Newsletter
Stay updated with the latest AI tools, news, and offers by subscribing to our weekly newsletter.
Related MCPs
Discover similar Model Context Protocol servers
WebScraping.AI MCP Server
MCP server for advanced web scraping and AI-driven data extraction
WebScraping.AI MCP Server implements the Model Context Protocol to provide web data extraction and question answering functionalities. It integrates with WebScraping.AI to offer robust tools for retrieving, rendering, and parsing web content, including structured data and natural language answers from web pages. It supports JavaScript rendering, proxy management, device emulation, and custom extraction configurations, making it suitable for both individual and team deployments in AI-assisted workflows.
- ⭐ 33
- MCP
- webscraping-ai/webscraping-ai-mcp-server
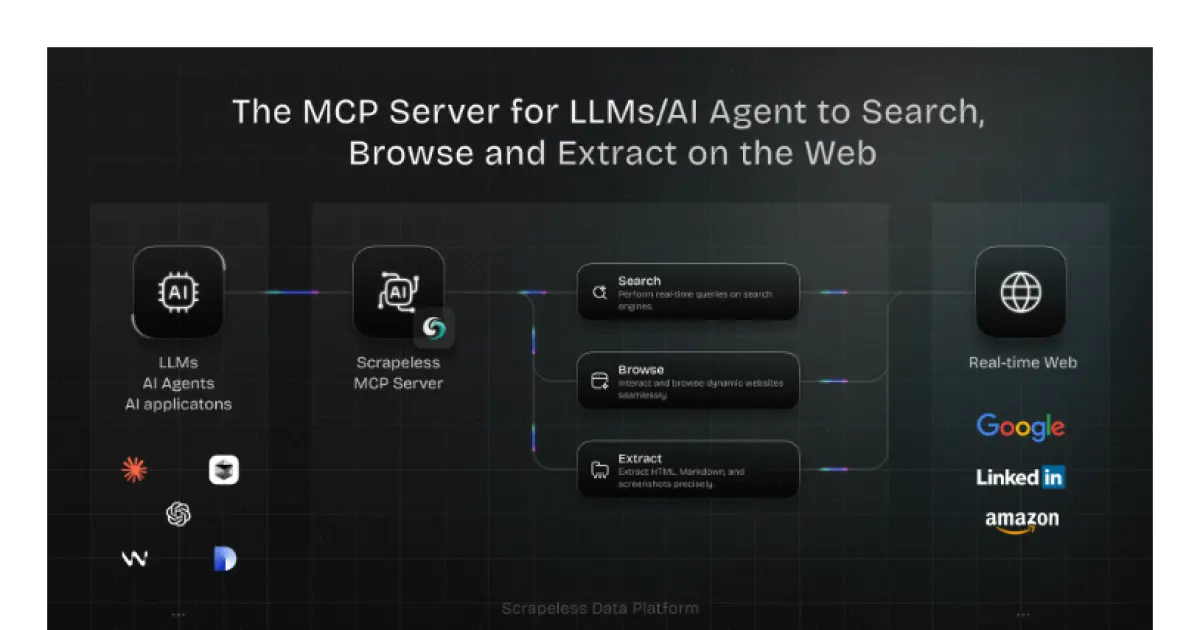
Scrapeless MCP Server
A real-time web integration layer for LLMs and AI agents built on the open MCP standard.
Scrapeless MCP Server is a powerful integration layer enabling large language models, AI agents, and applications to interact with the web in real time. Built on the open Model Context Protocol, it facilitates seamless connections between models like ChatGPT, Claude, and tools such as Cursor to external web capabilities, including Google services, browser automation, and advanced data extraction. The system supports multiple transport modes and is designed to provide dynamic, real-world context to AI workflows. Robust scraping, dynamic content handling, and flexible export formats are core parts of the feature set.
- ⭐ 57
- MCP
- scrapeless-ai/scrapeless-mcp-server
Driflyte MCP Server
Bridging AI assistants with deep, topic-aware knowledge from web and code sources.
Driflyte MCP Server acts as a bridge between AI-powered assistants and diverse, topic-aware content sources by exposing a Model Context Protocol (MCP) server. It enables retrieval-augmented generation workflows by crawling, indexing, and serving topic-specific documents from web pages and GitHub repositories. The system is extensible, with planned support for additional knowledge sources, and is designed for easy integration with popular AI tools such as ChatGPT, Claude, and VS Code.
- ⭐ 9
- MCP
- serkan-ozal/driflyte-mcp-server
Web Analyzer MCP
Intelligent web content analysis and summarization via MCP.
Web Analyzer MCP is an MCP-compliant server designed for intelligent web content analysis and summarization. It leverages FastMCP to perform advanced web scraping, content extraction, and AI-powered question-answering using OpenAI models. The tool integrates with various developer IDEs, offering structured markdown output, essential content extraction, and smart Q&A functionality. Its features streamline content analysis workflows and support flexible model selection.
- ⭐ 2
- MCP
- kimdonghwi94/web-analyzer-mcp
mcp-server-webcrawl
Advanced search and retrieval for web crawler data via MCP.
mcp-server-webcrawl provides an AI-oriented server that enables advanced filtering, analysis, and search over data from various web crawlers. Designed for seamless integration with large language models, it supports boolean search, filtering by resource types and HTTP status, and is compatible with popular crawling formats. It facilitates AI clients, such as Claude Desktop, with prompt routines and customizable workflows, making it easy to manage, query, and analyze archived web content. The tool supports integration with multiple crawler outputs and offers templates for automated routines.
- ⭐ 32
- MCP
- pragmar/mcp-server-webcrawl
DuckDuckGo Search MCP Server
A Model Context Protocol server for DuckDuckGo web search and intelligent content retrieval.
DuckDuckGo Search MCP Server provides web search capabilities through DuckDuckGo, with advanced content fetching and parsing tailored for large language models. It supports rate limiting, error handling, and delivers results in an LLM-friendly format. The server is designed for seamless integration with AI applications and tools like Claude Desktop, enabling enhanced web search and content extraction through the Model Context Protocol.
- ⭐ 637
- MCP
- nickclyde/duckduckgo-mcp-server
Didn't find tool you were looking for?