MarkItDown
Convert diverse files into Markdown for seamless LLM integration.
Key Features
Use Cases
README
MarkItDown


[!TIP] MarkItDown now offers an MCP (Model Context Protocol) server for integration with LLM applications like Claude Desktop. See markitdown-mcp for more information.
[!IMPORTANT] Breaking changes between 0.0.1 to 0.1.0:
- Dependencies are now organized into optional feature-groups (further details below). Use
pip install 'markitdown[all]'to have backward-compatible behavior.- convert_stream() now requires a binary file-like object (e.g., a file opened in binary mode, or an io.BytesIO object). This is a breaking change from the previous version, where it previously also accepted text file-like objects, like io.StringIO.
- The DocumentConverter class interface has changed to read from file-like streams rather than file paths. No temporary files are created anymore. If you are the maintainer of a plugin, or custom DocumentConverter, you likely need to update your code. Otherwise, if only using the MarkItDown class or CLI (as in these examples), you should not need to change anything.
MarkItDown is a lightweight Python utility for converting various files to Markdown for use with LLMs and related text analysis pipelines. To this end, it is most comparable to textract, but with a focus on preserving important document structure and content as Markdown (including: headings, lists, tables, links, etc.) While the output is often reasonably presentable and human-friendly, it is meant to be consumed by text analysis tools -- and may not be the best option for high-fidelity document conversions for human consumption.
MarkItDown currently supports the conversion from:
- PowerPoint
- Word
- Excel
- Images (EXIF metadata and OCR)
- Audio (EXIF metadata and speech transcription)
- HTML
- Text-based formats (CSV, JSON, XML)
- ZIP files (iterates over contents)
- Youtube URLs
- EPubs
- ... and more!
Why Markdown?
Markdown is extremely close to plain text, with minimal markup or formatting, but still provides a way to represent important document structure. Mainstream LLMs, such as OpenAI's GPT-4o, natively "speak" Markdown, and often incorporate Markdown into their responses unprompted. This suggests that they have been trained on vast amounts of Markdown-formatted text, and understand it well. As a side benefit, Markdown conventions are also highly token-efficient.
Prerequisites
MarkItDown requires Python 3.10 or higher. It is recommended to use a virtual environment to avoid dependency conflicts.
With the standard Python installation, you can create and activate a virtual environment using the following commands:
python -m venv .venv
source .venv/bin/activate
If using uv, you can create a virtual environment with:
uv venv --python=3.12 .venv
source .venv/bin/activate
# NOTE: Be sure to use 'uv pip install' rather than just 'pip install' to install packages in this virtual environment
If you are using Anaconda, you can create a virtual environment with:
conda create -n markitdown python=3.12
conda activate markitdown
Installation
To install MarkItDown, use pip: pip install 'markitdown[all]'. Alternatively, you can install it from the source:
git clone git@github.com:microsoft/markitdown.git
cd markitdown
pip install -e 'packages/markitdown[all]'
Usage
Command-Line
markitdown path-to-file.pdf > document.md
Or use -o to specify the output file:
markitdown path-to-file.pdf -o document.md
You can also pipe content:
cat path-to-file.pdf | markitdown
Optional Dependencies
MarkItDown has optional dependencies for activating various file formats. Earlier in this document, we installed all optional dependencies with the [all] option. However, you can also install them individually for more control. For example:
pip install 'markitdown[pdf, docx, pptx]'
will install only the dependencies for PDF, DOCX, and PPTX files.
At the moment, the following optional dependencies are available:
[all]Installs all optional dependencies[pptx]Installs dependencies for PowerPoint files[docx]Installs dependencies for Word files[xlsx]Installs dependencies for Excel files[xls]Installs dependencies for older Excel files[pdf]Installs dependencies for PDF files[outlook]Installs dependencies for Outlook messages[az-doc-intel]Installs dependencies for Azure Document Intelligence[audio-transcription]Installs dependencies for audio transcription of wav and mp3 files[youtube-transcription]Installs dependencies for fetching YouTube video transcription
Plugins
MarkItDown also supports 3rd-party plugins. Plugins are disabled by default. To list installed plugins:
markitdown --list-plugins
To enable plugins use:
markitdown --use-plugins path-to-file.pdf
To find available plugins, search GitHub for the hashtag #markitdown-plugin. To develop a plugin, see packages/markitdown-sample-plugin.
Azure Document Intelligence
To use Microsoft Document Intelligence for conversion:
markitdown path-to-file.pdf -o document.md -d -e "<document_intelligence_endpoint>"
More information about how to set up an Azure Document Intelligence Resource can be found here
Python API
Basic usage in Python:
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=False) # Set to True to enable plugins
result = md.convert("test.xlsx")
print(result.text_content)
Document Intelligence conversion in Python:
from markitdown import MarkItDown
md = MarkItDown(docintel_endpoint="<document_intelligence_endpoint>")
result = md.convert("test.pdf")
print(result.text_content)
To use Large Language Models for image descriptions (currently only for pptx and image files), provide llm_client and llm_model:
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(llm_client=client, llm_model="gpt-4o", llm_prompt="optional custom prompt")
result = md.convert("example.jpg")
print(result.text_content)
Docker
docker build -t markitdown:latest .
docker run --rm -i markitdown:latest < ~/your-file.pdf > output.md
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
How to Contribute
You can help by looking at issues or helping review PRs. Any issue or PR is welcome, but we have also marked some as 'open for contribution' and 'open for reviewing' to help facilitate community contributions. These are of course just suggestions and you are welcome to contribute in any way you like.
| All | Especially Needs Help from Community | |
|---|---|---|
| Issues | All Issues | Issues open for contribution |
| PRs | All PRs | PRs open for reviewing |
Running Tests and Checks
-
Navigate to the MarkItDown package:
shcd packages/markitdown -
Install
hatchin your environment and run tests:shpip install hatch # Other ways of installing hatch: https://hatch.pypa.io/dev/install/ hatch shell hatch test(Alternative) Use the Devcontainer which has all the dependencies installed:
sh# Reopen the project in Devcontainer and run: hatch test -
Run pre-commit checks before submitting a PR:
pre-commit run --all-files
Contributing 3rd-party Plugins
You can also contribute by creating and sharing 3rd party plugins. See packages/markitdown-sample-plugin for more details.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
Star History
Repository Owner

Organization
Repository Details
Programming Languages
Tags
Topics
Join Our Newsletter
Stay updated with the latest AI tools, news, and offers by subscribing to our weekly newsletter.
Related MCPs
Discover similar Model Context Protocol servers
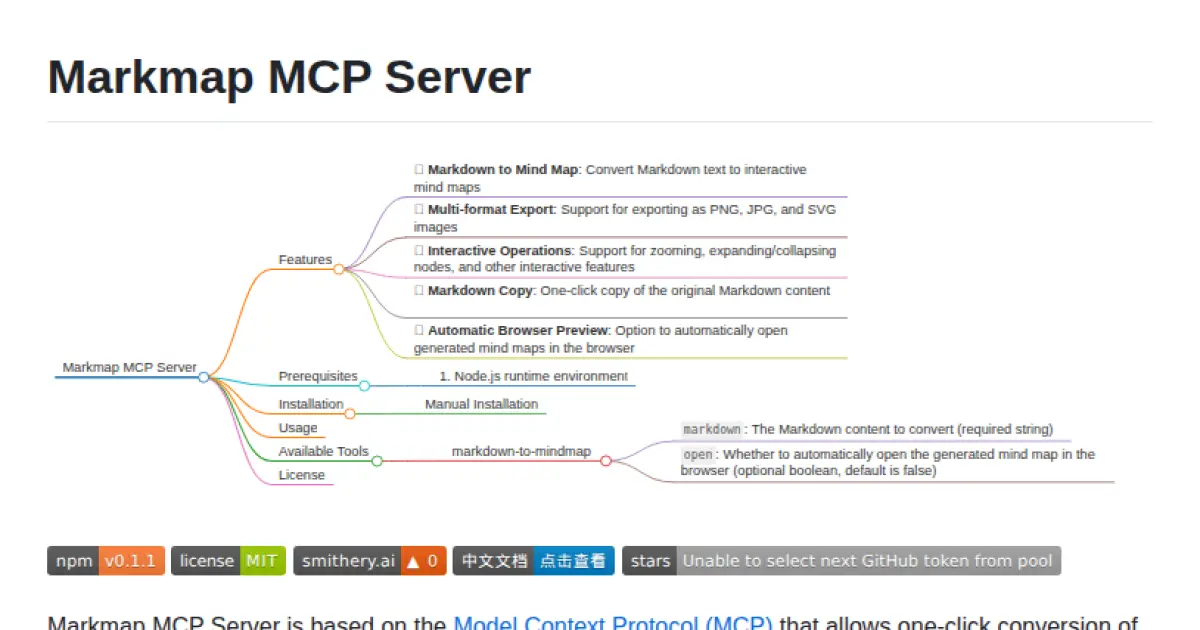
Markmap MCP Server
Convert Markdown to interactive mind maps via the Model Context Protocol.
Markmap MCP Server enables seamless conversion of Markdown content into interactive mind maps using the Model Context Protocol (MCP). It leverages the open-source markmap project and provides users with diverse export formats including PNG, JPG, and SVG. Designed for easy integration with MCP clients, it offers tools for automated browser previews, rich interactivity, and batch mind map generation. The server can be installed easily via npm or Smithery and supports configurable output directories.
- ⭐ 137
- MCP
- jinzcdev/markmap-mcp-server

PDF Tools MCP
Comprehensive PDF manipulation via MCP protocol.
PDF Tools MCP provides an extensive suite of PDF manipulation operations using the Model Context Protocol framework. It supports both local and remote PDF tasks, such as rendering pages, merging, extracting metadata, retrieving text, and combining documents. The tool registers endpoints through the MCP protocol, enabling seamless server-based PDF processing for various clients. Built with Python, it emphasizes secure handling and compatibility with Claude Desktop via the Smithery ecosystem.
- ⭐ 31
- MCP
- danielkennedy1/pdf-tools-mcp
mcp-read-website-fast
Fast, token-efficient web content extraction and Markdown conversion for AI agents.
Provides a Model Context Protocol (MCP) compatible server that rapidly fetches web pages, removes noise, and converts content to clean Markdown with link preservation. Designed for local use by AI-powered tools like IDEs and large language models, it offers optimized token usage, concurrency, polite crawling, and smart caching. Integrates with Claude Code, VS Code, JetBrains IDEs, Cursor, and other MCP clients.
- ⭐ 111
- MCP
- just-every/mcp-read-website-fast
Notion MCP Server
Enable LLMs to interact with Notion using the Model Context Protocol.
Notion MCP Server allows large language models to interface with Notion workspaces through a Model Context Protocol server, supporting both data retrieval and editing capabilities. It includes experimental Markdown conversion to optimize token usage for more efficient communication with LLMs. The server can be configured with environment variables and controlled for specific tool access. Integration with applications like Claude Desktop is supported for seamless automation.
- ⭐ 834
- MCP
- suekou/mcp-notion-server
OSP Marketing Tools for LLMs
Comprehensive marketing content creation and optimization tools for LLMs using MCP.
OSP Marketing Tools for LLMs offers a suite of marketing content creation and optimization utilities designed to operate with Large Language Models that support the Model Context Protocol (MCP). Built on Open Strategy Partners’ proprietary methodologies, it provides structured workflows for product value mapping, metadata generation, content editing, technical writing, and SEO guidance. The suite includes features for persona development, value case documentation, semantic editing, and technical writing best practices, enabling consistent and high-quality marketing outputs. Designed to integrate seamlessly with MCP-compatible LLM clients, it streamlines complex marketing processes and empowers efficient collaboration across technical and non-technical teams.
- ⭐ 252
- MCP
- open-strategy-partners/osp_marketing_tools
Content Core
AI-powered content extraction and processing platform with seamless model context integration.
Content Core is an AI-driven platform for extracting, formatting, transcribing, and summarizing content from a wide variety of sources including documents, media files, web pages, images, and archives. It offers intelligent auto-detection and engine selection to optimize processing, and provides integrations via CLI, Python library, Raycast extension, macOS Services, and the Model Context Protocol (MCP). The platform supports context-aware AI summaries and direct integration with Claude through MCP for enhanced user workflows. Users can access zero-install options and benefit from enhanced processing capabilities such as advanced PDF parsing, OCR, and smart summarization.
- ⭐ 85
- MCP
- lfnovo/content-core
Didn't find tool you were looking for?