 ReddRadar
ReddRadar
ApeRAG
Hybrid RAG platform with MCP integration for intelligent knowledge management
Key Features
Use Cases
README
ApeRAG
🚀 Try ApeRAG Live Demo - Experience the full platform capabilities with our hosted demo
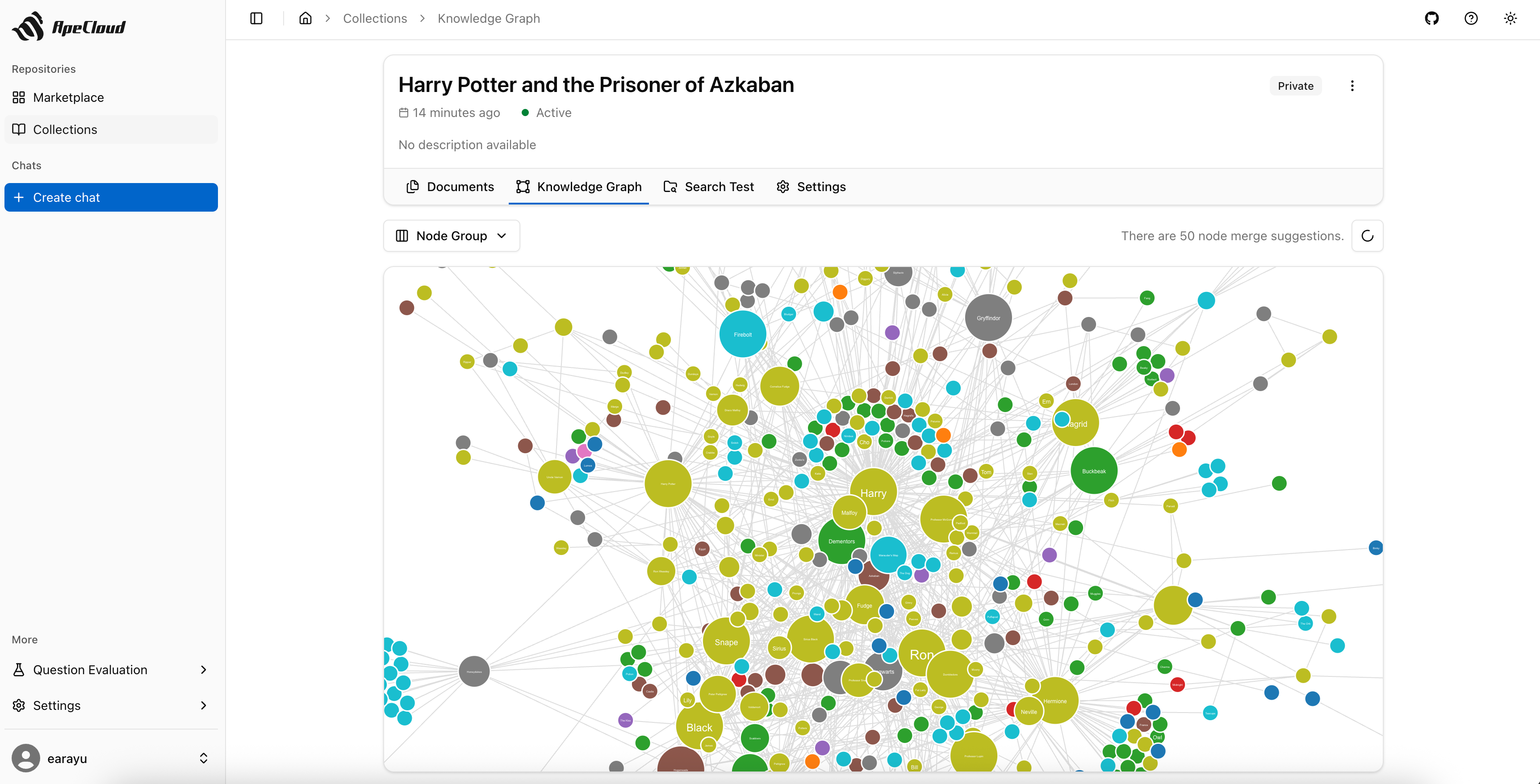
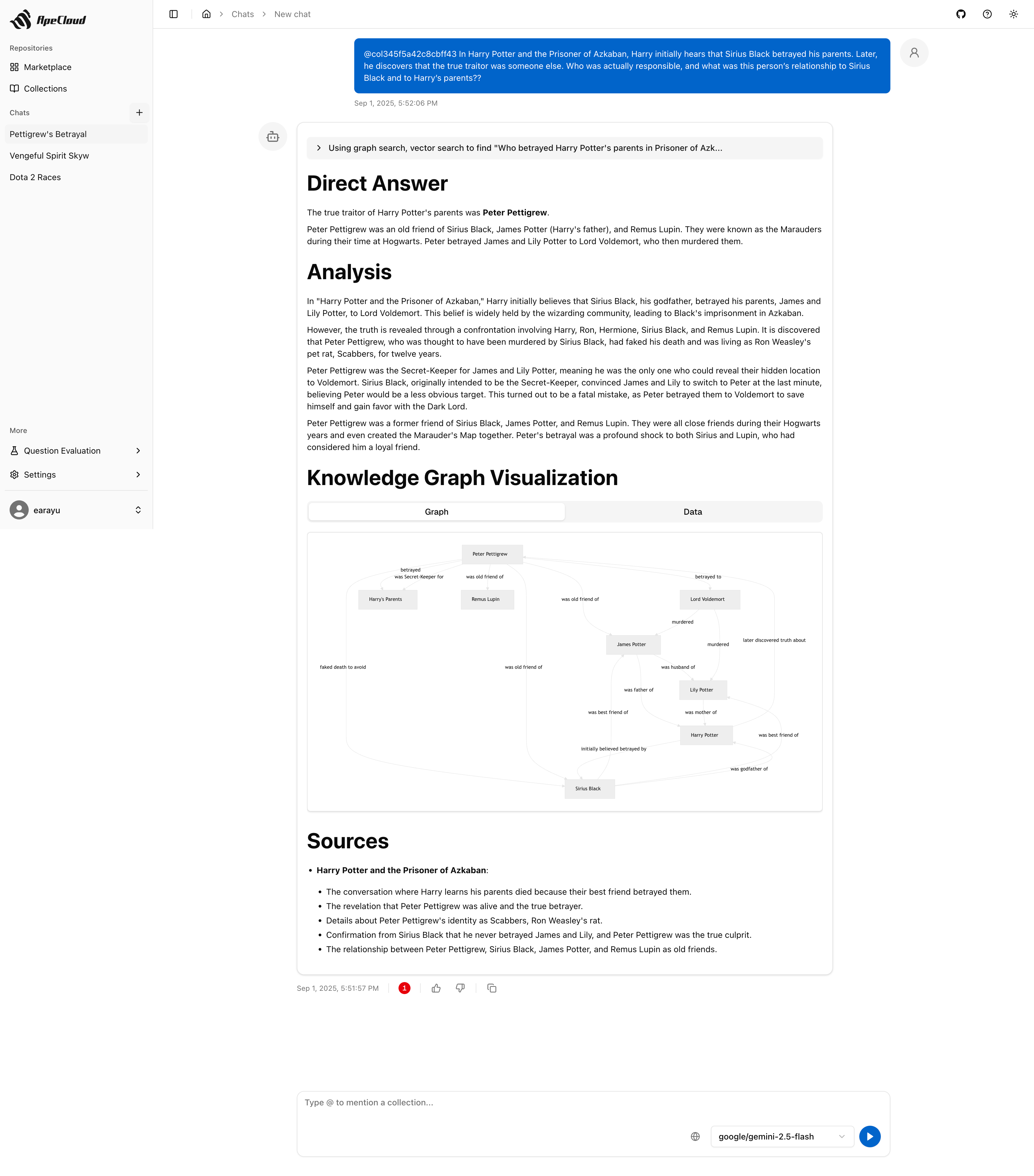
ApeRAG is a production-ready RAG (Retrieval-Augmented Generation) platform that combines Graph RAG, vector search, and full-text search with advanced AI agents. Build sophisticated AI applications with hybrid retrieval, multimodal document processing, intelligent agents, and enterprise-grade management features.
ApeRAG is the best choice for building your own Knowledge Graph, Context Engineering, and deploying intelligent AI agents that can autonomously search and reason across your knowledge base.
阅读中文文档
- Quick Start
- Key Features
- Kubernetes Deployment (Recommended for Production)
- Development
- Build Docker Image
- Acknowledgments
- License
Quick Start
Before installing ApeRAG, make sure your machine meets the following minimum system requirements:
- CPU >= 2 Core
- RAM >= 4 GiB
- Docker & Docker Compose
The easiest way to start ApeRAG is through Docker Compose. Before running the following commands, make sure that Docker and Docker Compose are installed on your machine:
git clone https://github.com/apecloud/ApeRAG.git
cd ApeRAG
cp envs/env.template .env
docker-compose up -d --pull always
After running, you can access ApeRAG in your browser at:
- Web Interface: http://localhost:3000/web/
- API Documentation: http://localhost:8000/docs
MCP (Model Context Protocol) Support
ApeRAG supports MCP (Model Context Protocol) integration, allowing AI assistants to interact with your knowledge base directly. After starting the services, configure your MCP client with:
{
"mcpServers": {
"aperag-mcp": {
"url": "https://rag.apecloud.com/mcp/",
"headers": {
"Authorization": "Bearer your-api-key-here"
}
}
}
}
Important: Replace http://localhost:8000 with your actual ApeRAG API URL and your-api-key-here with a valid API key from your ApeRAG settings.
The MCP server provides:
- Collection browsing: List and explore your knowledge collections
- Hybrid search: Search using vector, full-text, and graph methods
- Intelligent querying: Ask natural language questions about your documents
Enhanced Document Parsing
For enhanced document parsing capabilities, ApeRAG supports an advanced document parsing service powered by MinerU, which provides superior parsing for complex documents, tables, and formulas.
# Enable advanced document parsing service
DOCRAY_HOST=http://aperag-docray:8639 docker compose --profile docray up -d
# Enable advanced parsing with GPU acceleration
DOCRAY_HOST=http://aperag-docray-gpu:8639 docker compose --profile docray-gpu up -d
Or use the Makefile shortcuts (requires GNU Make):
# Enable advanced document parsing service
make compose-up WITH_DOCRAY=1
# Enable advanced parsing with GPU acceleration (recommended)
make compose-up WITH_DOCRAY=1 WITH_GPU=1
Development & Contributing
For developers interested in source code development, advanced configurations, or contributing to ApeRAG, please refer to our Development Guide for detailed setup instructions.
Key Features
1. Advanced Index Types: Five comprehensive index types for optimal retrieval: Vector, Full-text, Graph, Summary, and Vision - providing multi-dimensional document understanding and search capabilities.
2. Intelligent AI Agents: Built-in AI agents with MCP (Model Context Protocol) tool support that can automatically identify relevant collections, search content intelligently, and provide web search capabilities for comprehensive question answering.
3. Enhanced Graph RAG with Entity Normalization: Deeply modified LightRAG implementation with advanced entity normalization (entity merging) for cleaner knowledge graphs and improved relational understanding.
4. Multimodal Processing & Vision Support: Complete multimodal document processing including vision capabilities for images, charts, and visual content analysis alongside traditional text processing.
5. Hybrid Retrieval Engine: Sophisticated retrieval system combining Graph RAG, vector search, full-text search, summary-based retrieval, and vision-based search for comprehensive document understanding.
6. MinerU Integration: Advanced document parsing service powered by MinerU technology, providing superior parsing for complex documents, tables, formulas, and scientific content with optional GPU acceleration.
7. Production-Grade Deployment: Full Kubernetes support with Helm charts and KubeBlocks integration for simplified deployment of production-grade databases (PostgreSQL, Redis, Qdrant, Elasticsearch, Neo4j).
8. Enterprise Management: Built-in audit logging, LLM model management, graph visualization, comprehensive document management interface, and agent workflow management.
9. MCP Integration: Full support for Model Context Protocol (MCP), enabling seamless integration with AI assistants and tools for direct knowledge base access and intelligent querying.
10. Developer Friendly: FastAPI backend, React frontend, async task processing with Celery, extensive testing, comprehensive development guides, and agent development framework for easy contribution and customization.
Kubernetes Deployment (Recommended for Production)
Enterprise-grade deployment with high availability and scalability
Deploy ApeRAG to Kubernetes using our provided Helm chart. This approach offers high availability, scalability, and production-grade management capabilities.
Prerequisites
- Kubernetes cluster (v1.20+)
kubectlconfigured and connected to your cluster- Helm v3+ installed
Clone the Repository
First, clone the ApeRAG repository to get the deployment files:
git clone https://github.com/apecloud/ApeRAG.git
cd ApeRAG
Step 1: Deploy Database Services
ApeRAG requires PostgreSQL, Redis, Qdrant, and Elasticsearch. You have two options:
Option A: Use existing databases - If you already have these databases running in your cluster, edit deploy/aperag/values.yaml to configure your database connection details, then skip to Step 2.
Option B: Deploy databases with KubeBlocks - Use our automated database deployment (database connections are pre-configured):
# Navigate to database deployment scripts
cd deploy/databases/
# (Optional) Review configuration - defaults work for most cases
# edit 00-config.sh
# Install KubeBlocks and deploy databases
bash ./01-prepare.sh # Installs KubeBlocks
bash ./02-install-database.sh # Deploys PostgreSQL, Redis, Qdrant, Elasticsearch
# Monitor database deployment
kubectl get pods -n default
# Return to project root for Step 2
cd ../../
Wait for all database pods to be in Running status before proceeding.
Step 2: Deploy ApeRAG Application
# If you deployed databases with KubeBlocks in Step 1, database connections are pre-configured
# If you're using existing databases, edit deploy/aperag/values.yaml with your connection details
# Deploy ApeRAG
helm install aperag ./deploy/aperag --namespace default --create-namespace
# Monitor ApeRAG deployment
kubectl get pods -n default -l app.kubernetes.io/instance=aperag
Configuration Options
Resource Requirements: By default, includes doc-ray service (requires 4+ CPU cores, 8GB+ RAM). To disable: set docray.enabled: false in values.yaml.
Advanced Settings: Review values.yaml for additional configuration options including images, resources, and Ingress settings.
Access Your Deployment
Once deployed, access ApeRAG using port forwarding:
# Forward ports for quick access
kubectl port-forward svc/aperag-frontend 3000:3000 -n default
kubectl port-forward svc/aperag-api 8000:8000 -n default
# Access in browser
# Web Interface: http://localhost:3000
# API Documentation: http://localhost:8000/docs
For production environments, configure Ingress in values.yaml for external access.
Troubleshooting
Database Issues: See deploy/databases/README.md for KubeBlocks management, credentials, and uninstall procedures.
Pod Status: Check pod logs for any deployment issues:
kubectl logs -f deployment/aperag-api -n default
kubectl logs -f deployment/aperag-frontend -n default
Acknowledgments
ApeRAG integrates and builds upon several excellent open-source projects:
LightRAG
The graph-based knowledge retrieval capabilities in ApeRAG are powered by a deeply modified version of LightRAG:
- Paper: "LightRAG: Simple and Fast Retrieval-Augmented Generation" (arXiv:2410.05779)
- Authors: Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang
- License: MIT License
We have extensively modified LightRAG to support production-grade concurrent processing, distributed task queues (Celery/Prefect), and stateless operations. See our LightRAG modifications changelog for details.
Community
- Discord
- Feishu
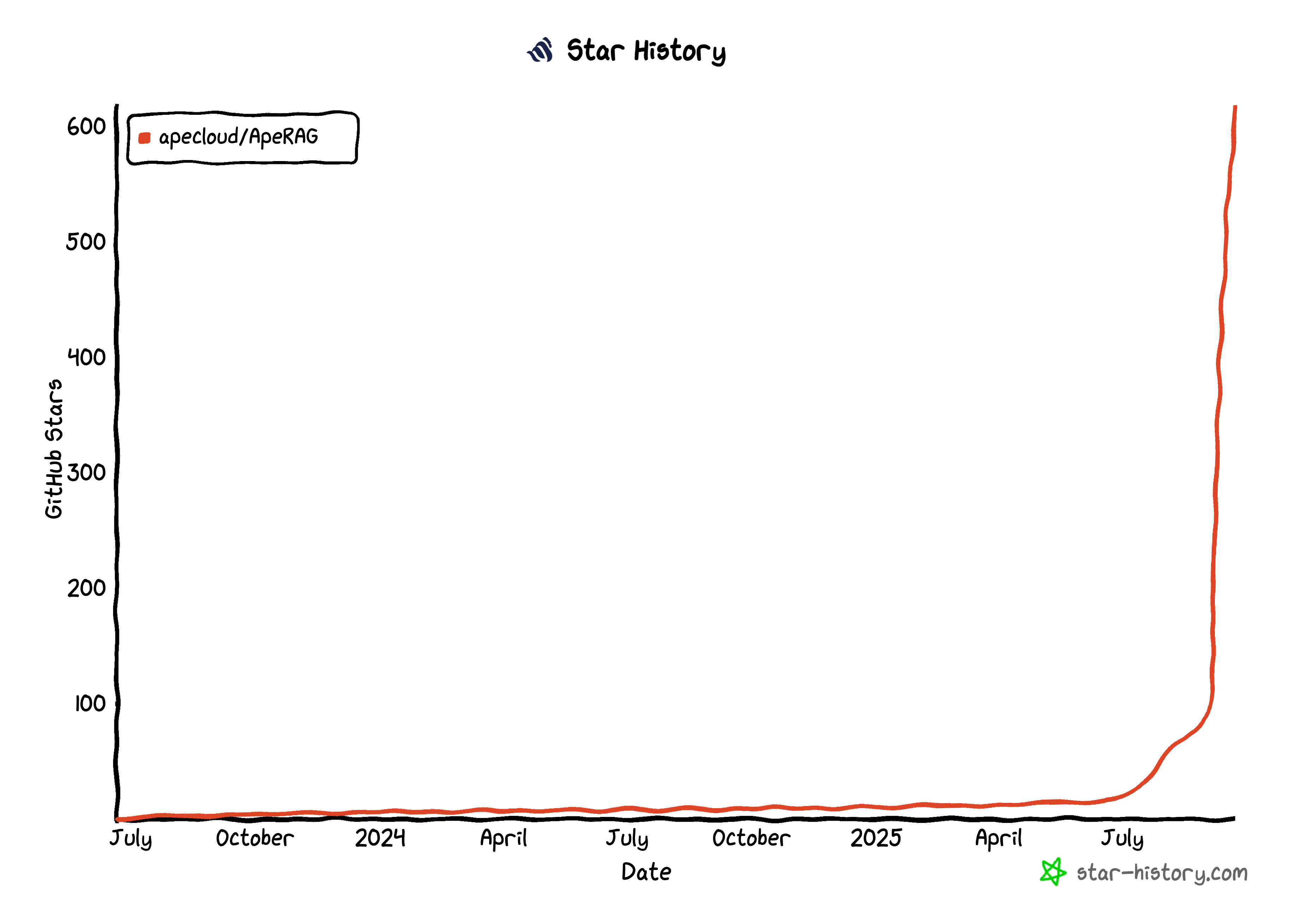
Star History
License
ApeRAG is licensed under the Apache License 2.0. See the LICENSE file for details.
Star History
Repository Owner

Organization
Repository Details
Programming Languages
Tags
Topics
Join Our Newsletter
Stay updated with the latest AI tools, news, and offers by subscribing to our weekly newsletter.
Related MCPs
Discover similar Model Context Protocol servers

Graphlit MCP Server
Integrate and unify knowledge sources for RAG-ready AI context with the Graphlit MCP Server.
Graphlit MCP Server provides a Model Context Protocol interface, enabling seamless integration between MCP clients and the Graphlit platform. It supports ingestion from a wide array of sources such as Slack, Discord, Google Drive, email, Jira, and GitHub, turning them into a searchable, RAG-ready knowledge base. Built-in tools allow for document, media extraction, web crawling, and web search, as well as advanced retrieval and publishing functionalities. The server facilitates easy configuration, sophisticated data operations, and automated notifications for diverse workflows.
- ⭐ 369
- MCP
- graphlit/graphlit-mcp-server
Ragie Model Context Protocol Server
Seamless knowledge base retrieval via Model Context Protocol for enhanced AI context.
Ragie Model Context Protocol Server enables AI models to access and retrieve information from a Ragie-managed knowledge base using the standardized Model Context Protocol (MCP). It provides a retrieve tool with customizable query options and supports integration with tools like Cursor and Claude Desktop. Users can configure API keys, specify partitions, and override tool descriptions. Designed for rapid setup via npx and flexible for project-specific or global usage.
- ⭐ 81
- MCP
- ragieai/ragie-mcp-server
RAG Documentation MCP Server
Vector-based documentation search and context augmentation for AI assistants
RAG Documentation MCP Server provides vector-based search and retrieval tools for documentation, enabling large language models to reference relevant context in their responses. It supports managing multiple documentation sources, semantic search, and real-time context delivery. Documentation can be indexed, searched, and managed with queueing and processing features, making it highly suitable for AI-driven assistants. Integration with Claude Desktop and support for Qdrant vector databases is also available.
- ⭐ 238
- MCP
- hannesrudolph/mcp-ragdocs
Driflyte MCP Server
Bridging AI assistants with deep, topic-aware knowledge from web and code sources.
Driflyte MCP Server acts as a bridge between AI-powered assistants and diverse, topic-aware content sources by exposing a Model Context Protocol (MCP) server. It enables retrieval-augmented generation workflows by crawling, indexing, and serving topic-specific documents from web pages and GitHub repositories. The system is extensible, with planned support for additional knowledge sources, and is designed for easy integration with popular AI tools such as ChatGPT, Claude, and VS Code.
- ⭐ 9
- MCP
- serkan-ozal/driflyte-mcp-server
MCP Local RAG
Privacy-first local semantic document search server for MCP clients.
MCP Local RAG is a privacy-preserving, local document search server designed for use with Model Context Protocol (MCP) clients such as Cursor, Codex, and Claude Code. It enables users to ingest and semantically search local documents without using external APIs or cloud services. All processing, including embedding generation and vector storage, is performed on the user's machine. The tool supports document ingestion, semantic search, file management, file deletion, and system status reporting through MCP.
- ⭐ 10
- MCP
- shinpr/mcp-local-rag
Trieve
All-in-one solution for search, recommendations, and RAG.
Trieve offers a platform for semantic search, recommendations, and retrieval-augmented generation (RAG). It supports dense vector search, typo-tolerant neural search, sub-sentence highlighting, and integrates with a variety of embedding models. Trieve can be self-hosted and features APIs for context management with LLMs, including Bring Your Own Model and managed RAG endpoints. Full documentation and SDKs are available for streamlined integration.
- ⭐ 2,555
- MCP
- devflowinc/trieve
Didn't find tool you were looking for?